

Article écrit par Cédric Brancourt
Le chemin à emprunter en suivant la direction DDD n’est pas si complexe qu’il n’y paraît. Il requiert, entre autres, de se débarrasser de certains réflexes et idées préconçues. Surtout de la fâcheuse tendance qu’on a de se projeter dans l’implémentation et la technique en zappant l’analyse du domaine. (Si vous n’êtes pas familier avec le DDD, je vous recommande de vous familiariser avec le sujet avant la lecture de cet article.)
C’est vrai aussi pour la question des permissions dans le système. Cette question revient très régulièrement. Comme toujours il n’y a pas de réponse universelle, mais il y a des orientations qu’il est bon de connaître l’heure du choix venue.
Comment faire cohabiter la notion de permission avec la modélisation du domaine ? C’est la question à laquelle je me propose de répondre dans cet article.
Questions / réponses
Pour introduire la question et la réponse, je vous rapporte une conversation que j’ai eue avec un architecte logiciel externe à l’œil perçant (monsieur X).
Je venais de présenter un diagramme qui détaille le flux de contrôle d’une commande (ci-dessous).
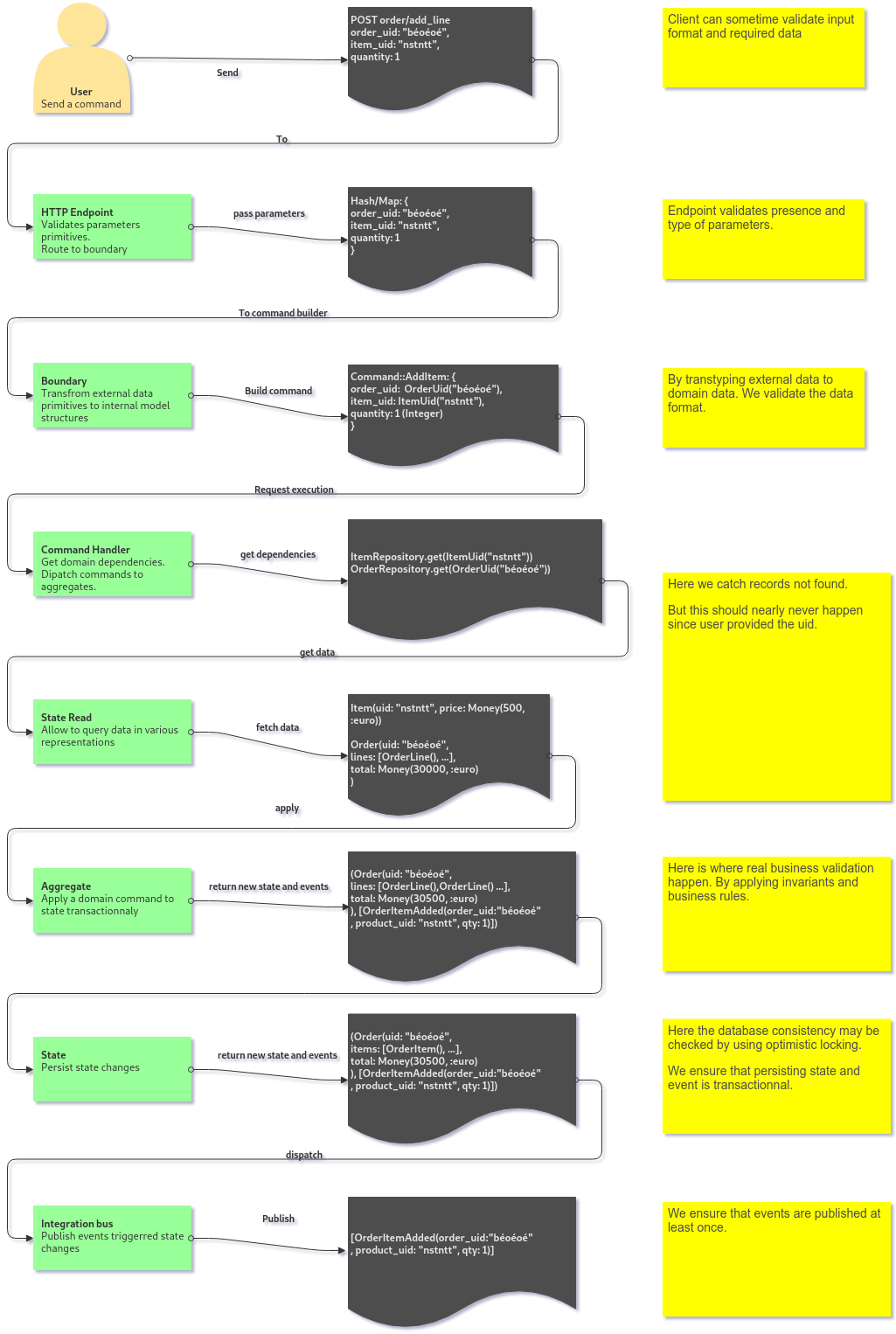
Voici les questions et réponses qui suivirent cette présentation.
x :
Dans ton modèle de flux pour l’exécution des commandes, tu places où le contrôle d’autorisation ?
cb :
Bonne question 🙂 Je distingue 2 choses : le rôle et la propriété. Je suppose que tu parles du rôle. Pour moi les rôles d’un utilisateur sont liés à son identité.
x :
Typiquement un utilisateur doit avoir le rôle X, Y ou Z pour effectuer une action donnée.
cb :
En règle générale je le mettrais dans les interactors/handlers.
x :
Du point de vue métier, c’est généralement exprimé comme précondition à un use case.
cb :
Oui, en effet c’est une précondition ou un argument requis. Parfois même une règle du domaine.
x :
Il y a quelque chose qui me chiffonne à l’idée de passer un objet “current user” à toutes mes commandes
cb :
Oui, tu remarqueras que je ne parle pas de current user. C’est plus qualifié que ça. Le rôle fait partie du jargon du domaine. Dans le cadre de la revue de document par exemple :
Dans mon review handler je transforme mon user en
reviewer_uidet je le passe a mon business tout simplement. Donc si je peux pas transformer mon user enreviewer_uid, c’est qu’une condition de permission n’est pas satisfaite. La réponse sera un échec pour cause de permission.x :
Et ton business va chercher les rôles ?
cb :
Non, si j’avais besoin de plus d’informations sur le reviewer dans mon domaine j’aurai un modèle reviewer en relation avec l’UID de l’utilisateur.
x :
Oui, d’office je ne comptais pas passer un objet avec des token oauth etc … 🙂
cb :
Si le rôle doit interagir avec le domaine au-delà d’une simple référence (UID), c’est le rôle que je passe (entité). Je trouve ça élégant car ça concilie la gestion du rôle et le domain model. La transformation du user en reviewer se fait dans la couche appli. Tandis que l’exploitation du reviewer se fait dans la couche domaine.
x :
Mais donc la responsabilité de vérifier l’autorisation revient au use case… ce qui peut élargir significativement le nombre de cas à tester :-
cb :
Non, je dirais plutôt dans la boundary. Son rôle est de transformer les objets du dehors vers ceux du domaine, ça te permet de «fail early» en validant les entrées.
x :
Oui ça fonctionne tant que la décision ne dépend pas des données qui vont être chargées dans le use case (typiquement une vérification de propriété)
cb :
Il n’y pas de «silver bullet» désolé 🙂 La propriété c’est radicalement différent. En tout cas selon moi. Elle serait plutôt un scope d’accès aux ressources.
x :
Oui t’as raison je pense que ce problème-là doit être réglé via le scoping, ça devrait plus souvent se terminer en “record not found” que “unauthorized” voilà 🙂
cb :
J’ai fait un article là-dessus y a longtemps. Où j’oriente vers des Activity Access control
x :
Ok je regarderai ça
cb :
Si tu le permets, je vais garder notre conversation pour que je puisse éclaircir le sujet plus tard dans le document.
Ce monsieur X a le don de poser les bonnes questions. Ce qui en fait un collaborateur à forte valeur ajoutée.
Il paraît que j’ai un don aussi : Quand quelqu’un me demande quelque chose, je lui explique comment s’en passer. C’est moisi comme super pouvoir.
Exemple concret
Par expérience nous utilisons des abstractions pour qualifier les composants logiciels lors de nos échanges. Mais cette pratique a la contrainte de n’être accessible qu’à ceux qui ont déjà l’expérience de l’abstraction en question.
Il faut donc du concret, de l’exemple. J’aime beaucoup les exemples, mais je redoute leur principal effet pervers : ils sont souvent pris au pied de la lettre. N’oublions pas de nous inspirer des exemples, mais gardons-nous de les reproduire.
Posons le contexte de l’exemple : Il s’agit d’un service qui permet de rédiger et publier des GTC.
Plusieurs processus sont inclus : rédiger un brouillon, publier un nouveau document à partir d’un brouillon, définir la version courante…
Nous allons nous intéresser seulement au cas de l’ajout d’un nouveau brouillon.
Puisque tout doit commencer par une analyse du domaine, parlons-en brièvement pour faire apparaître la notion de rôle dans le domaine.
Notre jargon du domaine pour l’instant se résume à «ajouter» et «brouillon».
Mais qui ? Dans notre contexte métier le brouillon est ajouté par son auteur.
Nous avons maintenant un use case complet. Un auteur ajoute un brouillon.
Le contexte technique dans notre exemple est déjà en place, car l’intégration se fait dans un système existant.
Bien qu’il ne soit pas essentiel au principe de base, le contexte du système l’est pour l’exemple. Je vais donc planter le décor.
Les services sont exposés au travers d’une API gateway. Elle est en charge de vérifier l’identité de l’utilisateur et d’enrichir la requête HTTP avec les propriétés liées.
Les requêtes qui parviennent aux services contiennent déjà l’UID de l’utilisateur, ainsi que ses rôles dans l’ensemble du système d’information. Ces derniers viennent d’une brique d’authentification historique et n’ont pas de portée dans le domaine actuel. Par exemple, le rôle «admin» n’a aucun sens dans le contexte du domaine de la publication de conditions contractuelles.
Un module rack (nommé MountApi) est en charge de filtrer et valider les paramètres reçus via HTTP. Ce qui nous affranchit de beaucoup de programmation défensive.
Voilà pour le background, revenons à nos moutons.
Nous avons une source d’authentification dont le rôle «admin» peut être un auteur de GTC. Faisons en sorte que notre code exprime le domaine.
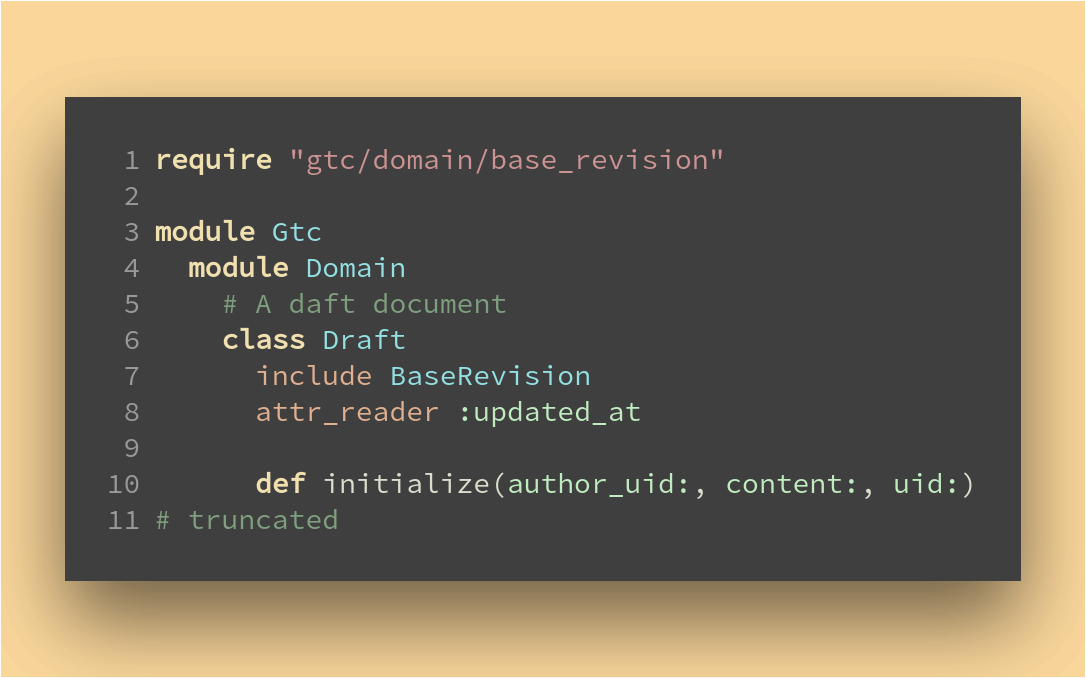
Notre aggregate Draft (ligne 10 ci-dessous) ne pourra pas s’initialiser sans author_uid. Ce qui évite de transiger avec les règles du domaine. Surtout dans le cadre d’un aggregate. Il en va de même pour toutes les méthodes du genre change_content(author_uid:, content:).
De ce fait notre couche domaine dispose de la notion d’auteur, ce dernier est indispensable à l’écriture d’un brouillon.
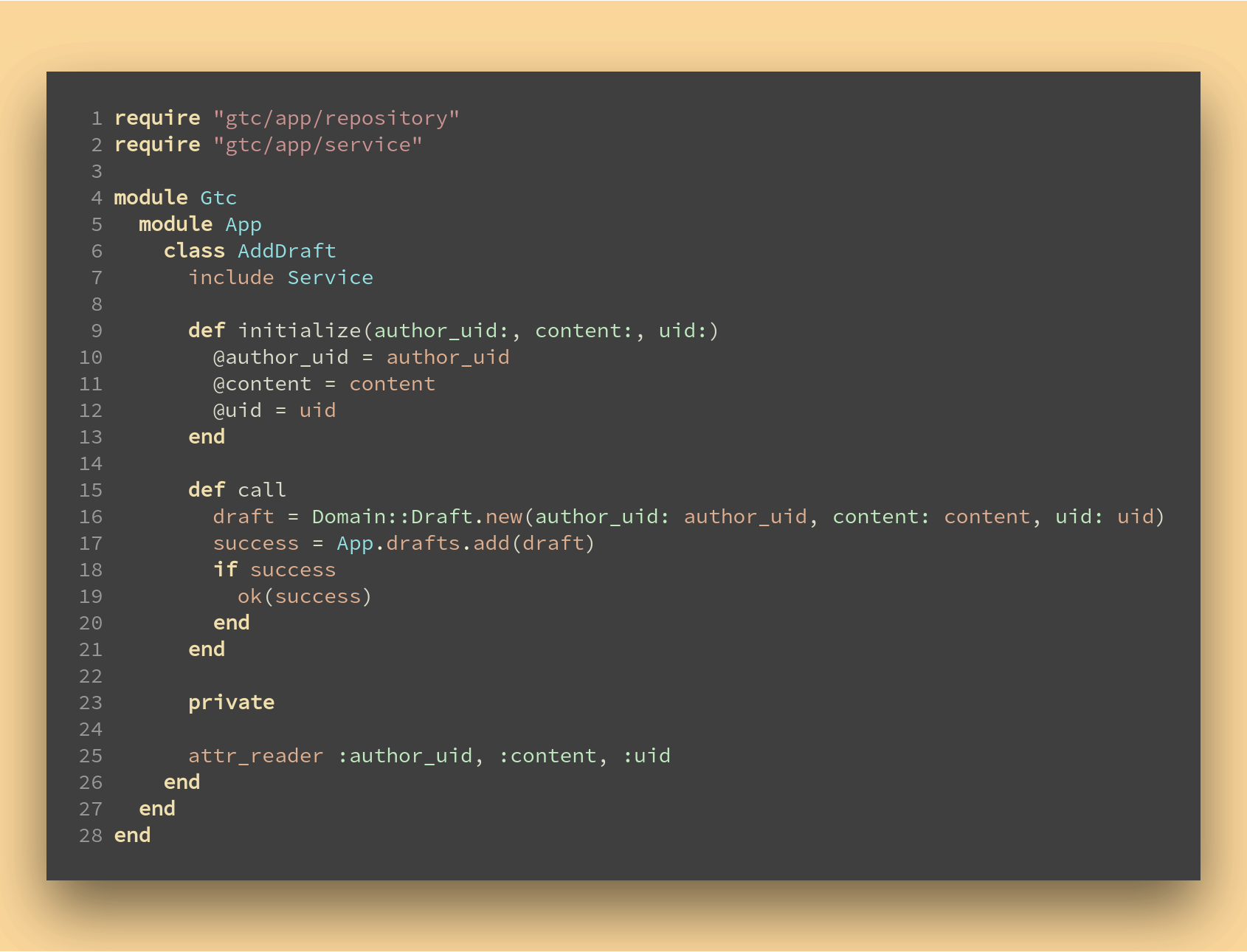
Si nous remontons dans la couche applicative (ligne 9 ci-dessous), notre service (command, interactor, use case) aura lui aussi besoin de ce paramètre qui doit lui être fourni, puisqu’il est une précondition au use case :
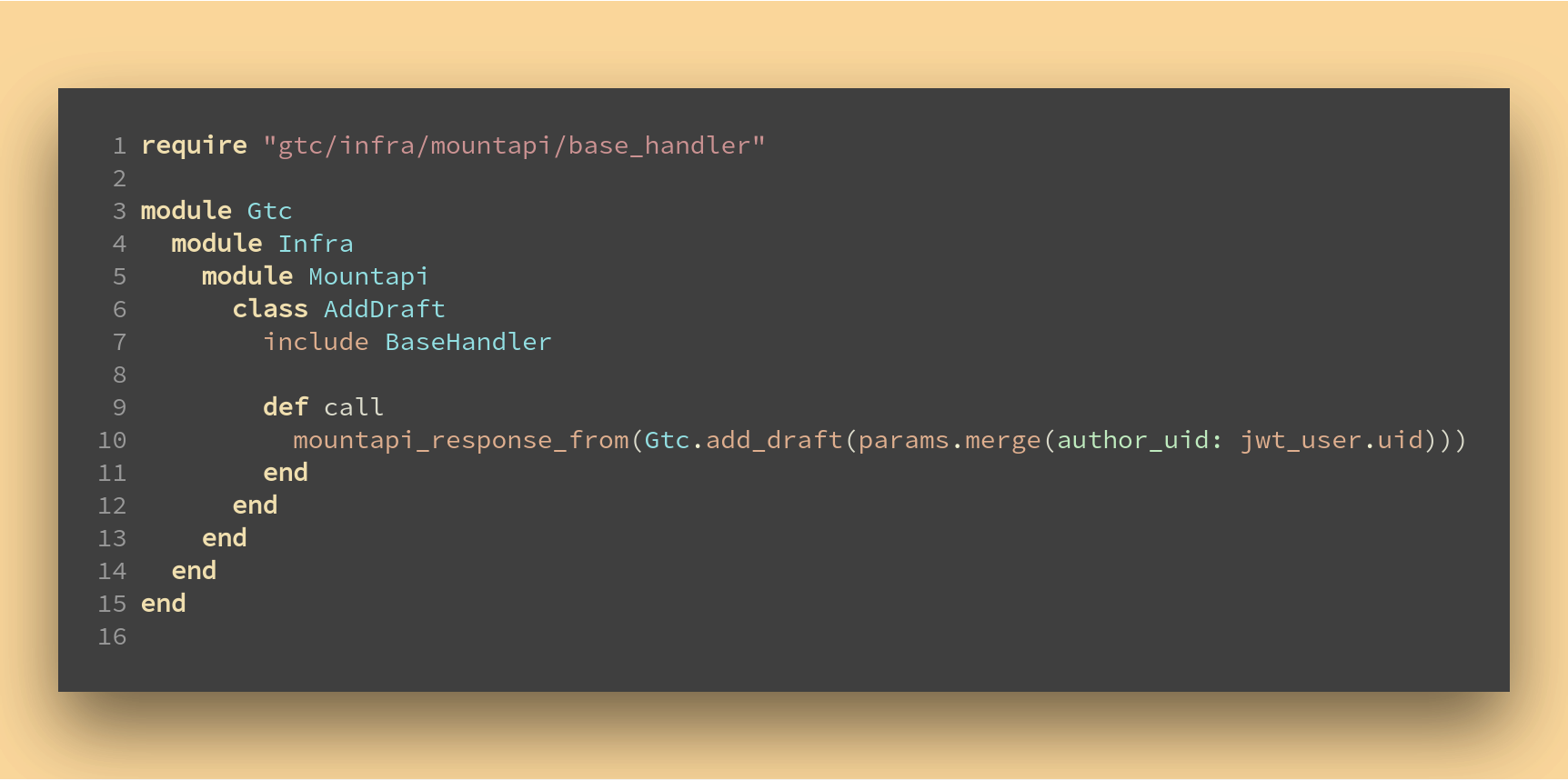
Pour finir c’est dans notre couche infrastructure que nous transformons les données externes en données internes.
Puisque par le canal HTTP nous obtenons des rôles avec la requête, notre handler est en charge de vérifier ceux-ci. Il agit comme une couche d’anti-corruption pour préserver les autres couches (App et Domain) et les garde centrées sur le domaine et isolées du reste du système.
C’est une fonctionnalité partagée à travers un mixin (BaseHandler ci-dessous).
La stratégie est simple :
Avec l’outil de gestion de permissions (ici activity_permission_engine), on enregistre le handler comme une activité (ligne 15).
Puis on autorise le rôle admin à effectuer cette activité (ligne 17).
Ensuite nous vérifions que l’utilisateur courant correspond bien à un des rôles pour lesquels l’activité est autorisée (lignes 11, et 22 à 27). S’il ne l’est pas une réponse appropriée est retournée sans aller plus loin.

À présent notre handler qui utilise le mixin BaseHandler peut se contenter de passer l’UID de l’utilisateur courant comme celui de l’auteur.
Dans notre exemple le contrôle de droits d’accès se fait au niveau de la couche infrastructure car les rôles n’ont rien de local à l’application puisqu’un contexte borné (bounded context) lui est dédié. Cependant dans le contexte borné du domaine de l’authentification ils seront partie prenante de l’application, voire du domaine.
Ces rôles externes ne franchissent jamais la frontière de la couche applicative. Et cette dernière n’utilise que des concepts qui font partie de son domaine d’application (auteur).
This is the end, my only friend…
Au-delà de l’exemple fourni il y a beaucoup de manières d’arriver au même résultat.
L’important c’est de bien identifier les zones de responsabilité de chaque couche (infrastructure, domaine, application). Éviter que l’implémentation des sessions (dans le giron de l’infrastructure) ne se répande partout dans les autres couches créant du couplage et brouillant la lisibilité (comme un current_user qui se balade dans les modèles). Et rendre visible, les rôles dans la couche domaine.
Il ne faudra surtout pas hésiter à implémenter le rôle comme un modèle local du domaine si les règles du métier rendent nécessaire l’interaction avec le domaine.
Tous ces principes peuvent être transposés, quel que soit le langage ou le framework. Ils peuvent nécessiter quelques ajustements mineurs en fonction de la nature du domaine (pour la brique d’authentification par exemple). Ils sont la pierre de Rosette de l’architecture du système.
À lire aussi

JTE : un moteur de templates moderne, rapide et sécurisé pour Java

La Sobriété Numérique, de la quantification des émissions carbone des applications à la mise en œuvre des corrections

Introduction pratique au Q-learning avec Gymnasium Taxi-v3
