

Article écrit par Quentin Buirette

Aujourd’hui, je vous propose un petit saut dans un univers parallèle pour y découvrir GraphQL.
Alors que les APIs REST ne cessent de prendre du terrain dans le paysage des applications web depuis ces 20 dernières années, GraphQL incarne un renouveau dans le genre. Nous allons tout de suite découvrir pourquoi !
GraphQL, une autre façon de concevoir des APIs
Commençons par le commencement.
D’ordinaire pour concevoir une API, nous nous serions concentrés sur la création de ressources matérialisées par des endpoints et une représentation des données (comprenez structure des données).
Voici un exemple de requête pour rechercher la fiche descriptive du film Guardians of the Galaxy Vol. 2 sur l’API d’OMDb via la commande curl :
curl http://www.omdbapi.com/?t=Guardians+of+the+galaxy+vol+2&apikey=YOUR_API_KEY => { "Title":"Guardians of the Galaxy Vol. 2", "Released":"05 May 2017", "Runtime":"136 min", "Genre":"Action, Adventure, Comedy, Sci-Fi", "Director":"James Gunn", ... } Cet exemple illustre l’essentiel des APIs que l’on retrouve aujourd’hui sur le web. On requête un endpoint pour accéder à une structure de données prédéfinie (on utilise implicitement ici le verbe HTTP GET). Si l’on souhaite accéder à d’autres ressources, il est nécessaire de requêter un autre endpoint en lui passant éventuellement d’autres paramètres en fonction du besoin. Bien évidemment, d’autres actions sont possibles, mais le rôle essentiel des APIs web aujourd’hui est de proposer un CRUD.
GraphQL nous propose une toute autre approche en nous permettant de récupérer seulement les données dont nous avons besoin.
Créé par Facebook à partir de 2012 pour faire face à des problématiques récurrentes de conception de leurs APIs, la première release publique interviendra seulement trois ans plus tard.
Bien plus qu’une nouvelle norme, GraphQL est un langage de requête à destination des APIs web.
Si vous découvrez, voici deux éléments importants à prendre en compte :
- On ne définit qu’un seul et unique endpoint (par exemple http://mon-site/graphql)
- Puisqu’il s’agit d’un langage de requête, toutes les actions se font par le biais d’un
POST
GraphQL vous permettra donc de faire disparaître la gestion des endpoints – parfois très difficile à documenter et à maintenir – et de créer des requêtes adaptées à votre besoin pour traiter la donnée, tout en ajoutant de la documentation au sein même du code.
En conséquence les développeurs frontend acquièrent de la flexibilité dans leur travail, car ils sont en mesure de manipuler les requêtes et de traiter les données comme ils l’entendent.
Intrigué ? Allons encore un peu plus loin dans la compréhension
GraphQL définit trois manières de requêter :
- Query : On va chercher une donnée précise (équivalent d’un
GET, mais en sélectionnant les attributs de notre choix) - Mutation : On veut faire évoluer la donnée (on peut le comparer aux actions
POST,PUTetDELETE) - Subscription : Cas un peu particulier qui permet de maintenir une connexion avec le serveur distant en faisant usage des websockets
Ce dernier cas est assez original dans le domaine des APIs web puisqu’il permet de s’affranchir de la notion stateless. Pour rappel cette notion fait référence à l’absence de gestion des états d’un client par le serveur. Ainsi, dans une architecture REST conventionnelle, il est nécessaire d’envoyer des informations à chaque requête (par exemple l’authentification), ce qui a tendance à alourdir le volume d’information qui transite sur les réseaux et joue sensiblement sur les performances.
GraphQL repose principalement sur un concept de schema. Un schema comprend plusieurs éléments dont la définition des actions comme les query, la définition des object types qui permettent de définir les attributs d’un objet que l’on va pouvoir manipuler avec GraphQL, ou encore des inputs qui vont permettre de lister les champs accessibles en paramètre d’une requête.
Par ailleurs, GraphQL possède son propre SDL (en) mais rien ne vous empêche de le déclarer autrement comme illustré dans l’exemple suivant :
const { GraphQLObjectType, GraphQLInt, GraphQLString } = require('graphql'); const MovieType = new GraphQLObjectType({ name: 'MovieType', description: 'MovieType attributes definition', fields: () => ({ title: { type: GraphQLString, description: 'Title of a movie' }, year: { type: GraphQLInt, description: 'Released year' } }); }); Voici le même exemple en utilisant cette fois-ci le SDL de GraphQL :
const { buildSchema } = require('graphql'); const MovieType = buildSchema(` """ MovieType attributes definition """ type MovieType { "Title of a movie" title: String! "Release year" year: Int! } `); Notez ici l’utilisation de template literal en JavaScript pour enrober notre définition de schéma, et également l’emploi de guillemets pour apposer une description que l’on retrouvera dans l’interface de développement de GraphQL que nous découvrirons plus loin dans cet article.
Enfin, il est nécessaire de mettre en place des resolvers dont le but est d’aller récupérer et de traiter la donnée.
Assez de discussion, place à l’action
Comme prévu, nous allons utiliser Node.js et même le framework Express.js pour nous amuser avec GraphQL. Notre mission – si nous l’acceptons – créer un wrapper (ou plus exactement une third party API) sur l’API d’OMDb qui contient des descriptions de film. Nous ne mettrons pas en place de logique de persistance, le but étant simplement de découvrir GraphQL.
Fondations
La première chose à faire est de découvrir l’API en question. Rendez-vous donc sur le site officiel pour se procurer une clé d’API et consulter la documentation.
La seconde étape ? Démarrer un projet Node, of course !
Dans votre terminal préféré :
- créer un nouveau répertoire et s’y rendre
- lancer
npm initpour configurer le nouveau projet - lancer
npm ipour créer notre fichier package.json - créer un fichier server.js (un autre nom convient tout aussi bien) qui servira de point d’entrée pour notre serveur
- créer un répertoire omdb/schema et un fichier schema.js qui contiendra la logique métier
- créer un répertoire omdb/resolvers et deux fichiers index.js et movie.js pour résoudre les différents accès à OMDb
mkdir graphql-omdb-api && cd $_ npm init npm i touch server.js mkdir -p omdb/schema && touch omdb/schema/schema.js mkdir omdb/resolvers && touch omdb/resolvers/{movies,index}.js Notre arborescence devrait donc ressembler à ça :
. ├── omdb │ ├── resolvers │ │ ├── index.js │ │ └── movies.js │ └── schema │ └── schema.js ├── package-lock.json ├── package.json └── server.js Maintenant, il est temps d’ajouter les dépendances dont nous aurons besoin pour ce projet :
npm install --save express express-graphql graphql body-parser node-fetch # Bonus : vous pouvez également installer Nodemon en local pour éviter d'avoir à relancer votre server à chaque changement npm install --save-dev nodemon NB : Si vous utilisez nodemon, n’oubliez pas de mettre à jour votre package.json en ajoutant une commande pour lancer le serveur comme illustré ci-dessous. Il vous suffira alors de lancer la commande npm start pour lancer votre serveur.
"scripts": { "start": "nodemon server.js", ... } Finalement, la dernière étape de configuration du projet consiste à implémenter notre serveur :
// ./server.js const express = require('express'); const bodyParser = require('body-parser'); const graphqlHTTP = require('express-graphql'); // Import du schema et du point d'entrée des resolvers const graphQlSchema = require('./omdb/schema/schema'); const graphQlResolvers = require('./omdb/resolvers/index'); const app = express(); // Ajout d'un middleware pour parser les données du corps de la requête en json // Pour en savoir plus sur body-parser : https://github.com/expressjs/body-parser app.use(bodyParser.json()); // Configuration du middleware GraphQL // 1) On ajoute le endpoint `/grapqhl` // 2) On utilise le package express-graphql pour la configuration // 3) On indique à GraphQL où chercher le schéma et les resolvers // 4) On active l'interface GraphQL (vous verrez, c'est magique !) app.use( '/graphql', graphqlHTTP({ schema: graphQlSchema, rootValue: graphQlResolvers, graphiql: true }) ); app.listen(4000, () => { console.log(`Server is listening on 4000`); }); Cette configuration serveur est suffisante en l’état, nul besoin d’aller plus loin.
Le schéma
Le schéma va nous permettre de définir nos objets GraphQL et de lister les différentes actions disponibles via notre API.
Ici, nous allons mettre en place deux queries :
- l’une pour rechercher un titre et optionnellement une année parmi une collection de films
- l’autre pour récupérer la fiche descriptive d’un film en fonction de son id en base de données
// ./omdb/schema/schema.js const { buildSchema } = require('graphql'); module.exports = buildSchema(` """ A MovieType refers to available attributes for Movie """ type MovieType { "Movie ID from OMDb" imdbID: ID! "Title of a movie" Title: String! "Released year" Year: String! "Released date" Released: String! "Small plot about the storyline" Plot: String! "Link to movie poster" Poster: String! } input MovieInput { title: String! year: String } type RootQuery { movies(movieInput: MovieInput): [MovieType!]! movie(movieId: String!): MovieType! } schema { query: RootQuery } `); Tâchons d’y voir un peu plus clair.
Dans un premier temps, on déclare un type MovieType qui va contenir la liste des attributs que l’on souhaite. Remarquez les différents types dit scalaires (scalar en anglais) comme ID ou String et l’usage d’un ! pour indiquer que le champ ne peut être null. Pour en savoir plus, je vous invite à consulter la documentation officielle de GraphQL concernant les scalar types et les object types.
Ensuite, on crée un input que l’on va pouvoir utiliser pour notre fonctionnalité de recherche de films, comme on peut le voir dans le type RootQuery juste en dessous. Là aussi nous nous retrouvons avec une syntaxe étrange : movies(movieInput: MovieInput): [MovieType!]!. Pour faire simple, on déclare une query movies qui prend en paramètre notre Hash MovieInput et qui devra retourner soit un tableau vide, soit un tableau qui contient des objets MovieType.
Enfin, il est nécessaire de déclarer notre schéma qui va lister nos queries et éventuellement nos mutations et nos subscriptions.
Nos resolvers pour récupérer les films depuis OMDb
Dans un premier temps, nous allons mettre en place un point d’entrée pour nos resolvers.
Reprenons le contenu de notre server.js. On y trouve les deux éléments suivants :
const graphQlResolvers = require('./omdb/resolvers/index');qui va nous permettre de charger tous les resolvers référencés dans./omdb/resolvers/index.js;- La configuration des resolvers GraphQL
graphqlHTTP({ rootValue: graphQlResolvers, etc..
// ./omdb/resolvers/index.js const movieResolver = require('./movies'); // rootResolver est un objet qui fait référence au contenu de notre movieResolver const rootResolver = { ...movieResolver // On ajoutera ici d'autres resolvers au besoin }; module.exports = rootResolver; Maintenant, la dernière chose à mettre en place est notre fameux movieResolver.
// ./omdb/resolvers/movies.js const fetch = require('node-fetch'); const baseURL = 'http://www.omdbapi.com/'; const searchQueryKey = '?s='; const movieIdQueryKey = '?i='; const yearOptionalQueryKey = '&y='; const apiKey = '&apikey=f229262c'; const omdbFetcher = args => { const fullURL = args.movieId ? findByMovieID(args.movieId) : searchFor(args.movieInput.title, args.movieInput.year); return fetch(fullURL) .then(response => response.json()) .catch(error => { throw new Error(error.Error) }); }; const findByMovieID = id => baseURL + movieIdQueryKey + id + apiKey; const searchFor = (title, year) => { return year ? baseURL + searchQueryKey + title + yearOptionalQueryKey + year + apiKey : baseURL + searchQueryKey + title + apiKey; }; module.exports = { movies: async args => { try { const movies = await omdbFetcher(args); return movies.Search; } catch (e) { console.log(e); } }, movie: async args => { try { const movie = await omdbFetcher(args); return movie; } catch (e) { console.log(e); } } }; En dehors de la logique de construction de l’URL qui pourrait être améliorée, notre intérêt réside ici dans le module.exports. On y trouve en effet nos deux requêtes : movies pour effectuer une recherche et movie pour consulter la fiche descriptive d’un film en fonction de son id.
Ces deux fonctions sont évidemment basiques. On vient récupérer les données de manière asynchrone et on les retourne. Au moindre problème, on soulève une exception.
Time to test it !
Maintenant que nous avons réalisé notre POC, nous allons pouvoir tester nos requêtes via l’interface de développement fournie par GraphQL.
Lançons notre serveur depuis la console :
npm start Puis rendons-nous dans notre navigateur préféré à l’adresse suivante : http://localhost:4000/graphql
Quelques petites choses à savoir sur cette interface :
- Autocomplétion : Sur Mac, on active l’autocomplétion avec
CTRL+SPACE - La documentation (récupérée depuis le code) est disponible via le menu latéral sur la droite
- Pour le reste c’est que du bonheur : syntax highlighting, remontée d’erreur en temps réel, résultat des requêtes, etc.
On peut désormais essayer nos requêtes directement depuis l’interface :
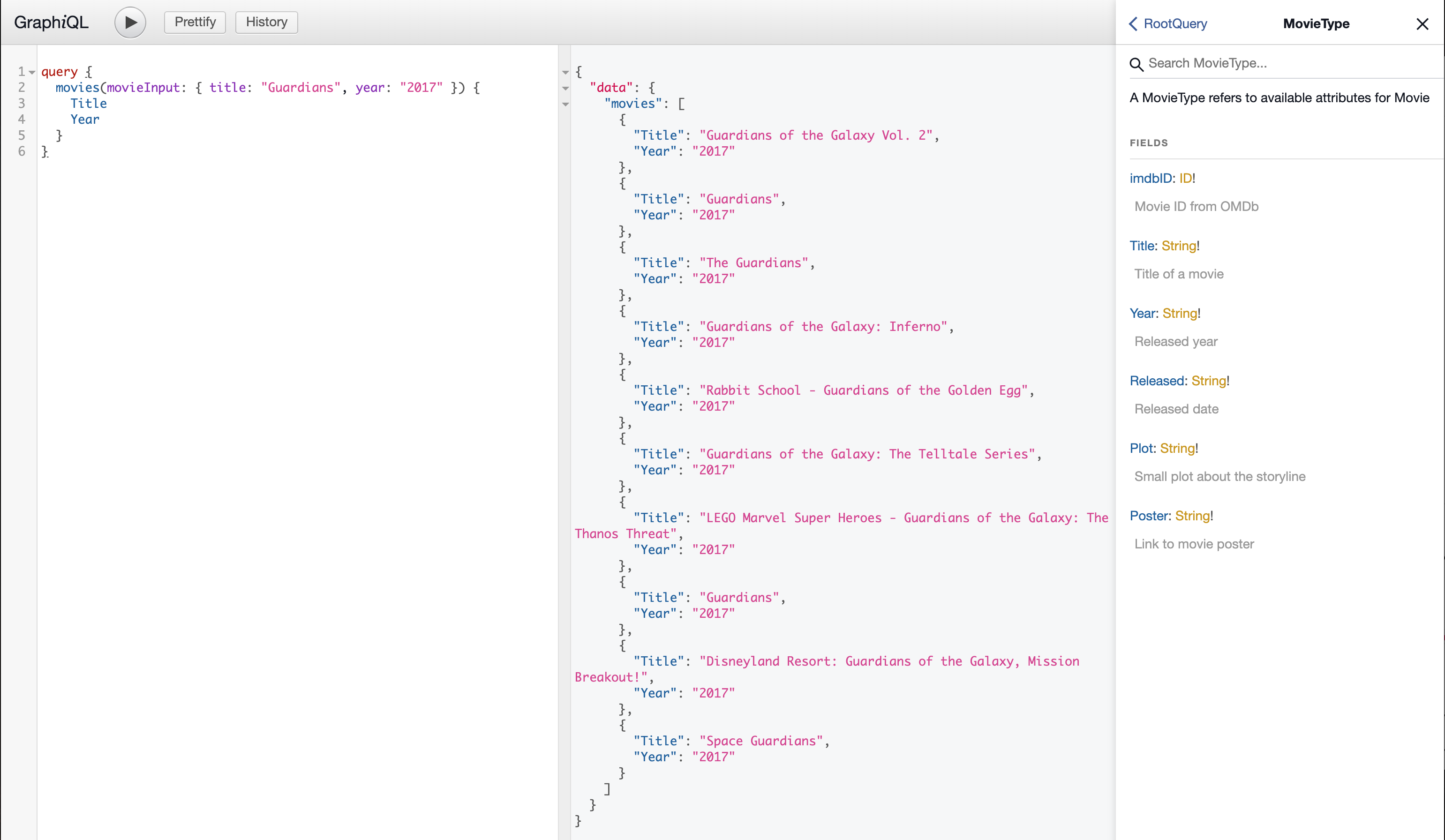
Libre à vous d’expérimenter comme vous l’entendez, d’ajouter une logique de persistance des données en créant des mutations, voire de vous essayer aux subscriptions ! Il est également possible d’exploiter des bibliothèques tierces comme la populaire Apollo que je vous invite à découvrir.
Quelques ressources supplémentaires pour aller plus loin :
- L’introduction officielle à GraphQL (en)
- Quelques Best practices disponible sur le site officiel (en)
- Un article intitulé Why Apollo : Advantages, Disadvantages & Alternatives (en)
- Un talk très intéressant intitulé REST vs GraphQL : Critical look, par Zdenek Nemec (en)
- Un retour d’expérience par l’un des créateurs de GraphQL, Lee Byron : Lessons from 4 Years of GraphQL (en)
À lire aussi

Diagnostiquer, comprendre et optimiser les performances d’une application React

Ouicommit Paris – IA : de l’expérimentation à l’industrialisation

Ouidou et Scaleway : un partenariat stratégique pour accélérer le cloud souverain en Europe


