

Ecrit par Florent Vollmer

Git est de loin la technologie de versioning la plus utilisée aujourd’hui. Dans de nombreuses formations en informatique, la notion de versioning, ou gestion de versions pour les puristes, est considérée comme triviale et très rapidement vue. C’est pourtant une des premières choses dont on a besoin en entreprise, puisque cela vous permet de partager votre travail avec vos collègues, et plus généralement de travailler de façon plus structurée et plus sereine même en local : plus besoin de collectionner d’innombrables copies d’un même projet “juste au cas où” sur votre machine !
Pour vous aider à tirer parti de Git, cet article va rapidement expliquer les principales fonctionnalités de Git en mettant l’accent sur celles le plus souvent utilisées en entreprise. Son but n’est en rien d’être une documentation complète de git, laquelle peut être trouvée ici : https://git-scm.com/doc.
Vous remarquerez l’accent certain sur l’utilisation de Git par lignes de commande. En effet, bien qu’il existe de nombreuses interfaces graphiques très pratiques pour cet outil, les plus populaires et/ou intéressantes peuvent rapidement changer, et l’interface par invite de commande sera toujours votre moyen le plus certain de savoir ce que vous faites.
Fonctionnement et commandes de base
La majorité des opérations faites avec Git se font entièrement en local, sur le schema ci-dessous, et ne concernent donc que les cadres « Répertoire local » et « Staging ».
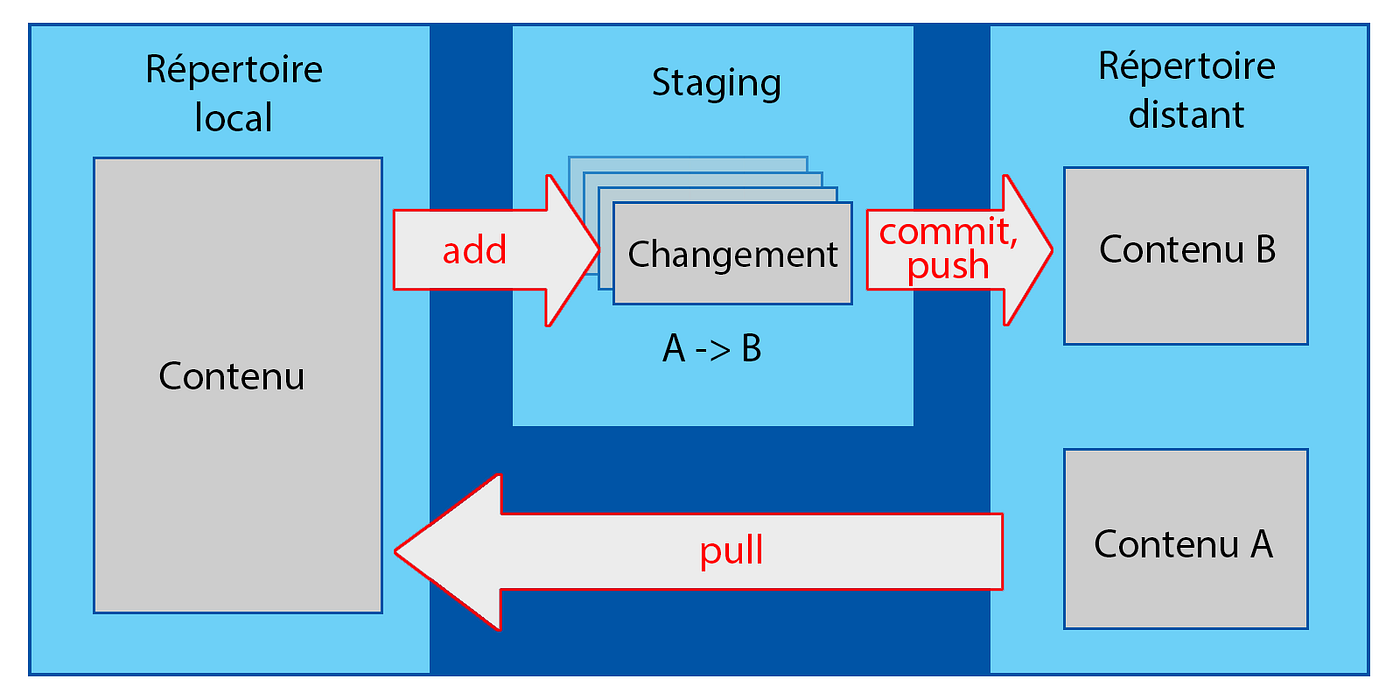
La première étape lorsqu’on récupère le code d’un projet est d’exécuter la commande « git clone », qui va créer le répertoire local (On pourra ensuite mettre celui-ci à jour avec la commande « git pull »). On a ainsi une copie complète du projet chez soi, sur laquelle on va faire nos changements.
Une fois les changements faits, on utilise la commande « git add <fichier_1> <fichier_2> <fichier_n> » (synonyme de git stage) afin de sélectionner les changements que l’on veut partager sur le répertoire distant, fichier par fichier. C’est ce qu’on appelle ajouter les fichiers à l’index, ou « staging area ». Très souvent, on voudra sélectionner tous les changements, auquel cas on fera simplement « git add . » C’est aussi à ce moment-là que vous voudrez sans doute utiliser la commande « git status », qui vous affichera un résumé des changements ajoutés et non ajoutés.
Une fois les changements sélectionnés, on peut créer un commit avec la commande « git commit ». Si vous voulez le créer en une seule commande, vous pouvez entrer « git commit -m <description> » et ainsi directement le créer avec sa description. Sans cette option « -m », git vous demandera d’écrire la description avec un éditeur de texte que vous aurez choisi lors de l’installation de git.
Enfin, il vous reste à partager le commit créé avec la commande « git push ». En l’absence de conflit, le commit est alors ajouté à la branche courante dans le répertoire distant.
En résumé :
« git pull » récupère les ressources depuis le répertoire distant
« git add » sélectionne les modifications à ajouter au prochain commit que l’on va créer
« git commit » crée le commit
« git push » upload le ou les commits créés vers le répertoire distant
La gestion des branches
En plus de répartir les changements de codes dans des commits successifs, on peut répartir ces commits sur différentes « branches ». Cela est pratique surtout pour le travail collaboratif sur un répertoire, et quand plusieurs fonctionnalités sont développées parallèlement.
Un modèle communément accepté de gestion des branches est le git-flow, dont un cycle peut être résumé par le schéma ci-dessous :
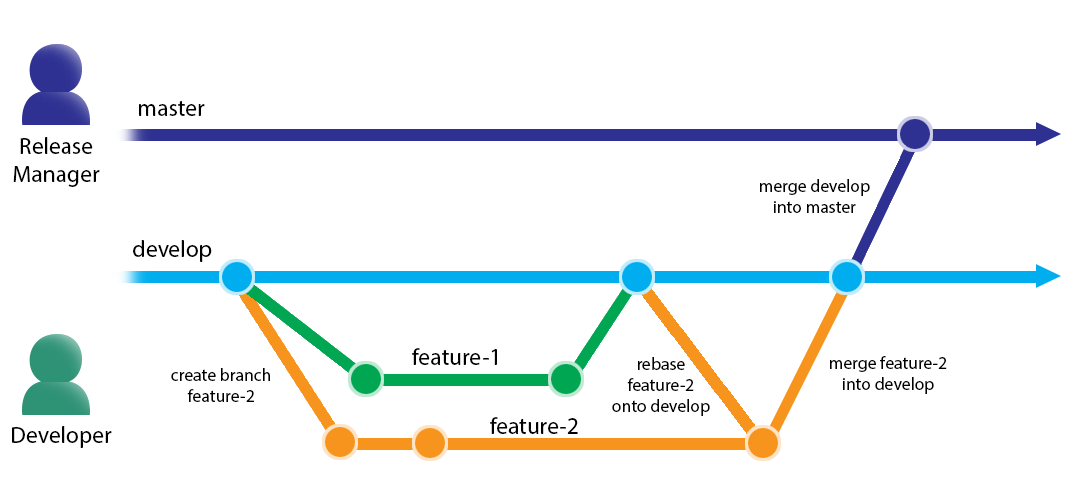
La branche « master » est celle hébergeant la version du code en production, tandis que develop sert de référence aux développeurs tirant leurs nouvelles branches.
On voit que deux branches de fonctionnalités, « feature-1 » et « feature-2 » y sont développées simultanément. S’il peut être tentant de travailler indéfiniment sur sa branche « feature » et ainsi ne jamais avoir de conflits avec les changements des autres, il est recommandé de ne pas le faire plus longtemps que nécessaire et donc « merger » sa branche dans develop dès la fonctionnalité terminée. De plus, on peut « rebase » une branche depuis une autre, comme ici feature-2 sur develop, afin de travailleur sur une version plus récente du code, et de gérer d’éventuels conflits avant le merge.
Une fois les fonctionnalités développées et mergées dans develop, le release manager peut merger develop dans master et créer une nouvelle version de déploiement, souvent symbolisées par un « tag » sur master.
Voyons maintenant comment appliquer ce modèle grâce via des commandes git :
Création d’une nouvelle branche
Admettons que vous soyez sur la branche « develop » d’un projet. Pour push des modifications sur une nouvelle branche « ma-branche », vous aurez à exécuter, dans cet ordre :
git checkout -b ma-branche
git add .
git commit
git push
Vous constaterez que la seule nouveauté ici est la commande « checkout », qui crée la branche. Les trois suivantes consistent simplement à commit et push les modifications sur cette nouvelle branche, plutôt que la branche de départ. Pour revenir à une branche déjà existante, on peut réutiliser la commande checkout, mais cette fois sans l’option « -b ».
Fusionner deux branches
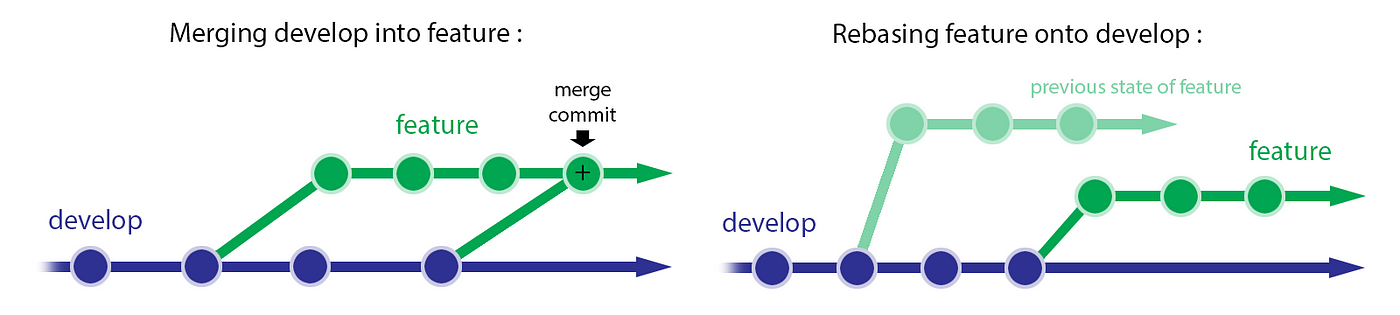
La différence entre merge et rebase peut ne pas paraître évidente. On préfère d’ailleurs parfois la commande « merge » à la commande « rebase » pour mettre à jour une branche feature par rapport à une branche principale, et l’example de rebase donné dans le schéma du git-flow ci-dessus pourrait aussi bien représenter un merge.
En effet, un rebase ne crée pas de nouveau commit, mais modifie l’historique, de telle sorte que les commits de la branche que l’on rebase apparaissent après ceux de la branche sur laquelle on rebase. À l’inverse, un merge crée un nouveau commit mais ne modifie pas l’historique des commits précédents. Rebase permet donc d’avoir un historique plus propre, tandis que le merge est non-destructif et donc plus sécurisé, ce qui explique pourquoi le on préfère généralement sur les branches develop et master.
Questions fréquentes
Voici maintenant quelques réponses à des problèmes que vous rencontrerez sans doute assez vite :
« Je ne voulais pas add ce fichier ! »
Vous pouvez entrer « git reset <fichier> » pour enlever ce fichier de l’index ou « git reset » pour enlever tous les fichiers ajoutés. Cela n’aura aucun effet sur le contenu des fichiers sur le disque, c’est simplement l’inverse de la commande « git add ».
« Je ne voulais pas créer ce commit / je veux changer quelque chose à ce commit que je viens de créer »
Vous pouvez utiliser la commande « git reset --soft HEAD~1 ». Cela n’aura pas d’autre effet que d’annuler la création du commit (à condition de ne pas oublier l’option --soft), là encore les fichiers sur le disque resteront intacts. En effet, « HEAD~1 » représente l’avant-dernier commit de la branche courante, et –soft le fait de garder tous les changements. L’option --hard en revanche, vous permettra de supprimer tous les changements du disque si c’est ce que vous voulez faire.
« Je ne peux pas push car il y a un conflit »
Cette situation vous arrivera fatalement si vous n’êtes pas le seul à travailler sur un projet. Cela veut dire que la version locale et la version distante ont toutes deux été modifiées, et que Git n’arrive pas à « deviner » comment concilier ces modifications qui sont parfois contradictoires. Il va alors placer des marqueurs de conflits dans le code, à chaque endroit demandant votre intervention pour résoudre le conflit. Dans cette situation, utiliser Git via une interface graphique peut être bien plus ergonomique que la console Git. Une fois les conflits résolus vous pourrez push normalement.
« Je voudrais mettre ces modifications de côté pour l’instant »
Vous vous êtes sans doute déjà retrouvés avec une multitude de versions d’un même projet sur votre ordinateur, au cas où vous « casseriez tout » avec des changements difficiles à inverser. Si les commandes précédemment citées réduisent déjà ce risque, vous serez peut-être aussi intéressés par la commande « git stash » (déplace les changements non-commités vers un stash) et ses variantes « git stash pop » (applique et supprime le dernier stash) et « git stash apply » (applique le dernier stash), qui est comme un presse-papier multiple à l’échelle de votre répertoire local. Plus de détails et cas d’utilisations sont trouvables dans la documentation officielle de cette commande très pratique et flexible.
À lire aussi

JTE : un moteur de templates moderne, rapide et sécurisé pour Java

La Sobriété Numérique, de la quantification des émissions carbone des applications à la mise en œuvre des corrections

Introduction pratique au Q-learning avec Gymnasium Taxi-v3
