

Article écrit par Thusitha Lakshan
Pourquoi versionner sa base de données ?
Il est important pour nous d’avoir une réponse assez claire pour cette question.
Une base de données a besoin d’être versionnée car :
- elle évolue avec son application, surtout dans un contexte agile,
- un retour arrière de l’application peut souvent impliquer une nécessité d’un retour arrière de sa base de données,
- elle doit avoir le même état entre les différents développeurs et les différents environnements
Le versioning de base de données nous permet également de suivre les différentes évolutions qui ont été apportées à la base de données plus facilement.
Qu’est-ce que Liquibase ?
Liquibase est un outil open-source de migrations de base de données écrit en Java.
Il nous permet de suivre les différentes évolutions dans une base de données (création, modification, suppression, insertion). Il est également compatible avec plusieurs bases de données que ce soit relationnelle (Oracle, PostgreSQL, MySQL…) ou encore NoSQL (Cassandra, MongoDB…).
Ce dernier peut être utilisé de plusieurs façons :
- en ligne de commande avec CMD
- en utilisant des tâches Ant
- en utilisant des commandes Maven
- en utilisant Spring Boot
Comment il fonctionne ?
Les différentes évolutions de notre base de données sont stockées dans des fichiers :
- XML
- YAML
- JSON
Au démarrage du projet, Liquibase va analyser ces différents fichiers et comparer avec la version actuelle de la base de données afin d’identifier les nouvelles instructions.
Ces instructions sont découpées en 3 niveaux :
- le master changelog (master.xml) : il s’agit du fichier parent dans lequel sont listées toutes les instructions que Liquibase doit exécuter dans l’ordre indiqué.
- le changelog (fichier nommé comme nous le souhaitons) : il regroupe la liste des évolutions à un moment donné.
- le changeset (un bloc dans le changelog) : il s’agit d’une instruction d’évolution.
Nous avons donc le changeset dans lequel nous allons spécifier les différentes évolutions à apporter à notre base de données. Le changelog va contenir 1 ou plusieurs de ces instructions et finalement, une référence à ce dernier est ajouté dans le fichier master.xml.
Comment l’intégrer à un projet Spring Boot ?
Ajouter les dépendances
Pour ajouter Liquibase sur un projet Spring Boot, il suffit d’ajouter le code suivant dans le pom.xml du projet :
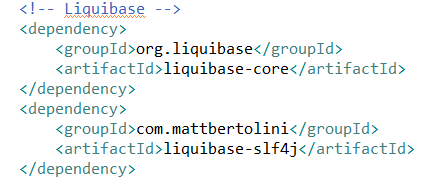
Configurer Liquibase sur notre projet
La configuration de Liquibase se fait dans le fichier application.properties de notre projet. Il nous suffit d’ajouter les lignes suivantes :
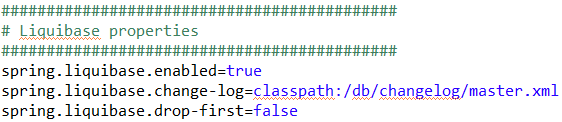
Signification des paramètres :
- spring.liquibase.enabled : Activer/Désactiver Liquibase
- spring.liquibase.change-log : Lien vers le fichier listant les différentes instructions de migration
- spring.liquibase.drop-first : Si Liquibase doit d’abord vider la base de données avant la migration
Comment effectuer notre première migration ?
Pour notre exemple, nous allons supposer une base de données Oracle très simple avec une seule table contenant 3 colonnes :Table USERS {
id NUMBER(19,0),
nom VARCHAR2(255 CHAR),
prenom VARCHAR2(255 CHAR)
}
Au bout de quelques versions livrées, nous avons besoin d’ajouter une nouvelle colonne “date_creation” à cette table.
Nous allons donc, en utilisant Liquibase, créer un nouveau changlog pour cette évolution. Pour ce faire, nous avons 3 possibilités :
En utilisant les tags prédéfinis par Liquibase :
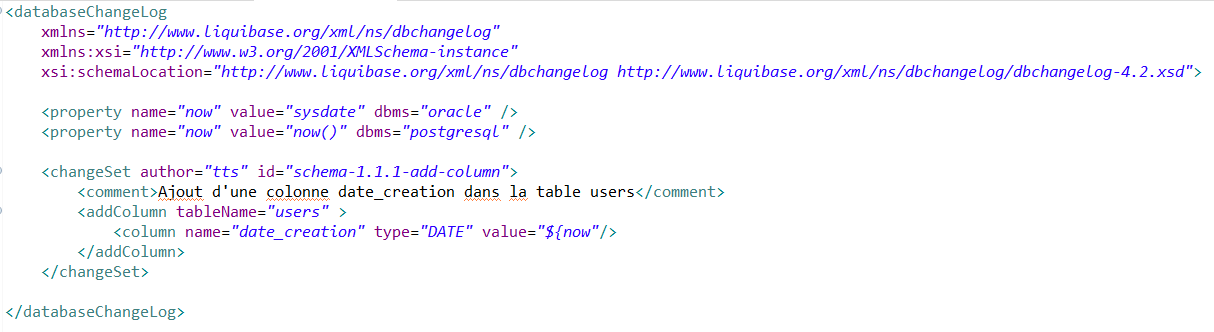
L’avantage avec cette solution est que nous pouvons définir des propriétés pour plusieurs environnements et faire une seule instruction que Liquibase va exécuter avec la bonne valeur (ici la valeur par défaut de notre nouvelle colonne est la date courante et sa récupération diffère entre Oracle et PostgreSQL). Cette dernière est également facilement lisible et compréhensible.
En utilisant la requête SQL :
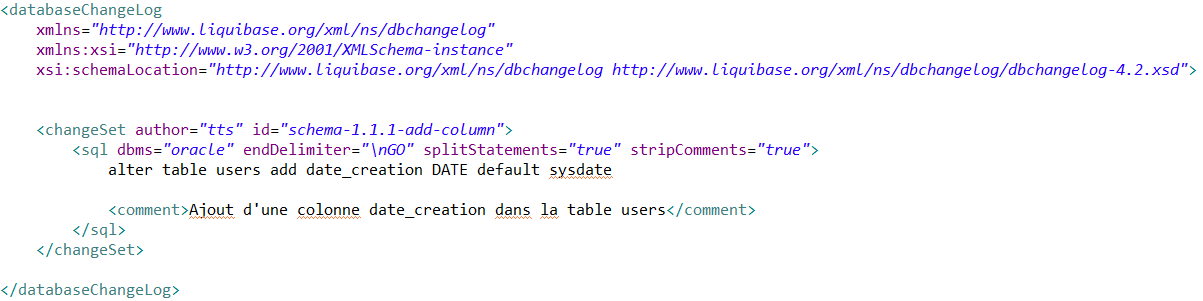
La différence notable avec cette solution est que même si nous avons la liberté d’écrire l’instruction SQL par nous même, nous ne pouvons pas écrire une instruction pour plusieurs environnements (exemple ici avec la valeur par défaut de notre colonne).
En référençant un fichier SQL contenant l’instruction :

Cette solution est semblable à la précédente car il s’agit du même mode de fonctionnement. La seule différence ici est que nous référençons un fichier SQL au lieu d’écrire directement notre instruction SQL.
Mon avis sur ces solutions
De mon point de vue, la meilleure solution pour des instructions simples est la première car elle est beaucoup plus simple à écrire et à lire.
Par contre, si nous avons besoin de par exemple créer une procédure assez complexe, la dernière solution serait la meilleure à adopter. Je m’explique, même si les 2 dernières solutions se ressemblent, avoir un fichier SQL contenant l’instruction nous permet d’avoir une meilleure lisibilité et une meilleure maintenabilité.
Ajouter notre changelog dans Liquibase
Une fois que nous avons créé notre fichier changelog, il nous faut l’ajouter dans le fichier “master.xml” pour que Liquibase l’exécute lors du démarrage de notre projet.

Nous aurons donc une structure semblable à celle-ci :
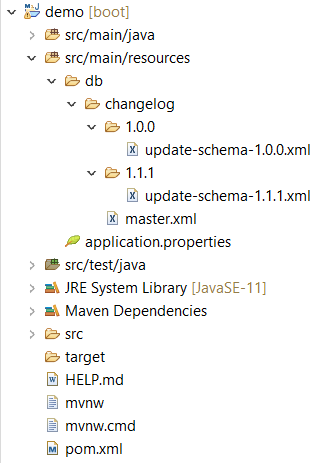
Remarque
Il est important de bien découper nos différents changelogs dans des dossiers séparés pour avoir une meilleure visibilité. Pour cela, nous pouvons par exemple définir que le nom du dossier sera la version de l’application contenant les évolutions.
Il est également important de bien nommer le fichier changelog. Nous pouvons découper ce dernier en plusieurs catégories :
– Un changelog contenant uniquement des évolutions concernant le schéma, nommé par exemple “1.1.1-schema.xml”
– Un changelog contenant uniquement des mises à jour des données, nommé par exemple “1.1.1-data.xml”
Comment vérifier que Liquibase a bien lancé notre instruction ?
L’historisation des évolutions de la base de données est effectuée dans une table nommée “DATABASECHANGELOG”.
Les champs de cette table qui nous intéressent sont les suivantes :
- ID : contient l’id du changeset. Nous aurrons donc “schema-1.1.1-add-column”.
- AUTHOR : contient l’auteur renseigné dans le changeset. Nous aurons donc “tts”.
- FILENAME : contient le lien vers le fichier de changelog.
- DATEEXECUTED : la date d’exécution du changelog.
- ORDEREXECUTED : l’ordre d’exécution.
- EXECTYPE : nous donne l’information sur le statut de l’exécution.
- MD5SUM : checksum unique créé pour chaque changeset.
- COMMENTS : le commentaire du changeset.
Au démarrage de notre projet, Liquibase va donc insérer une nouvelle ligne dans cette table :

Au prochain démarrage, notre instruction d’ajout de colonne ne sera pas relancée étant donné que la ligne est insérée dans cette table. Egalement, Liquibase va vérifier l’intégrité des évolutions précédentes en comparant le checksum (champ “MD5SUM”) avec celui qui est dans cette table. Ainsi, si nous modifions un changeset déjà exécuté, Liquibase va arrêter la migration et nous signaler qu’une évolution déjà exécutée a été altérée.
Liquibase nous permet également de définir dans quel contexte il doit exécuter telle ou telle instruction. Nous pouvons ainsi définir des changelogs à lancer uniquement en local, uniquement en recette etc.
Conclusion
Nous avons pu voir les avantages en utilisant un outil de versioning de base de données et comment utiliser Liquibase. Avoir un outil comme Liquibase facilite la vie des développeurs car nous n’avons plus besoin de lancer manuellement les scripts SQL, chacun peut utiliser une base de données en local tout en ayant le même état.
Pour aller plus loin
Si vous êtes curieux, voici le lien vers la documentation officielle qui est très complète :
À lire aussi

JTE : un moteur de templates moderne, rapide et sécurisé pour Java

La Sobriété Numérique, de la quantification des émissions carbone des applications à la mise en œuvre des corrections

Introduction pratique au Q-learning avec Gymnasium Taxi-v3
