

Article écrit par Martin
Entouré de mes acolytes Gaëtan et Nicolas nous étions mercredi 10 mai à la conférence "We Love Speed". Cette conférence itinérante s'arrêtait cette année à Paris, à l'espace Saint Martin.
Les sujets des conférences gravitent évidemment tous autour de la performance et plus précisément de la web performance. Le principal focus se trouve notamment sur les aspects front. Je pense que c'est d'ailleurs un axe qui pourrait évoluer pour couvrir des pans plus larges de la performance (infrastructure, pattern côté back-end…).
On peut toutefois se féliciter d'avoir ce type de conférence avec des intervenants d'excellent niveau.
Dans cet article, nous allons donc vous retracer les différentes conférences et ateliers que nous avons pu voir et ce que nous en avons retenu.
Entouré de mes acolytes Gaëtan et Nicolas nous étions mercredi 10 mai à la conférence "We Love Speed". Cette conférence itinérante s'arrêtait cette année à Paris, à l'espace Saint Martin.
Les sujets des conférences gravitent évidemment tous autour de la performance et plus précisément de la web performance. Le principal focus se trouve notamment sur les aspects front. Je pense que c'est d'ailleurs un axe qui pourrait évoluer pour couvrir des pans plus larges de la performance (infrastructure, pattern côté back-end…).
On peut toutefois se féliciter d'avoir ce type de conférence avec des intervenants d'excellent niveau.
Dans cet article, nous allons donc vous retracer les différentes conférences et ateliers que nous avons pu voir et ce que nous en avons retenu.
Dompter l’Impact en Webperf des Scripts Tiers
Andy Davies nous parle de l’impact des scripts third party dans la performance web.Si les fonctionnalités offertes (analytics, RUM, contenu) ne sont pas à remettre en cause, il est nécessaire de trouver un équilibre. Un bon outil pour obtenir une cartographie des requêtes réalisées pour un site donné : Request Map Generator.
Andy propose la classification des contenus suivante pour déterminer quand charger quoi :

Il nous ouvre également les yeux sur les problématiques de vie privée ouvertes par les scripts tiers. La fuite d’IP vers un domaine tiers sans consentement a notamment été récemment l’objet d’un procès en Allemagne.
Il s’interroge sur l’intérêt de proposer des API de consentement intégrées au navigateur, ce qui leur conférerait encore plus de pouvoirs. Les CDN également commencent à proposer des alternatives (ex : cloudflare zaraz).
Par ailleurs, les chargements sur des sites tiers, aussi rapides soient ils, s’avèrent souvent plus lents que des chargements locaux. Tous les scripts third party ne sont pas égaux et ils doivent également être monitorés. Il est nécessaire de définir précisément ce qu’on veut mesurer (taille, nombre de requêtes…). Par exemple, Google Tag Manager est très lourd à charger.
Certaines lib (ex : postscribe) implémentent des fonctionnalités qui sont potentiellement très peu utilisées et avec des impacts majeurs en termes de performance (dans ce cas
Il s’interroge sur l’intérêt de proposer des API de consentement intégrées au navigateur, ce qui leur conférerait encore plus de pouvoirs. Les CDN également commencent à proposer des alternatives (ex : cloudflare zaraz).
Par ailleurs, les chargements sur des sites tiers, aussi rapides soient ils, s’avèrent souvent plus lents que des chargements locaux. Tous les scripts third party ne sont pas égaux et ils doivent également être monitorés. Il est nécessaire de définir précisément ce qu’on veut mesurer (taille, nombre de requêtes…). Par exemple, Google Tag Manager est très lourd à charger.
Certaines lib (ex : postscribe) implémentent des fonctionnalités qui sont potentiellement très peu utilisées et avec des impacts majeurs en termes de performance (dans ce cas
document.write.)Enfin, le simple fait de ré-ordonner les tags peut parfois amener des gains de performance significatifs. Ces gains sont d’ailleurs souvent synonymes de revenus plus importants.
Les Protocoles Web pour les devs front-end
Dans cette conférence de Robin Marx, qui offre un parallèle surprenant avec le Seigneur des Anneaux, il est question (d’épées et) de protocoles, principalement d’HTTP.Actuellement, nous en sommes à HTTP/3 (basé sur QUIC), qui offre l’avantage d’être pleinement rétrocompatible avec HTTP/2. L’activer pour un site compatible H2 est donc sans risque.

Robin se positionne du point de vue des CDN (il travaille pour l’un d’eux).
Pour un CDN, il est difficile de connaître le nombre de paquets qu’il est possible d’envoyer.
En effet, côté client, la taille d’un lien est fixe mais souvent partagée entre plusieurs connexions, qui vont et qui viennent. Il est donc difficile de connaître précisément la capacité de la connexion à un instant T. Les CDN en sont donc réduits à l’estimer, de manière progressive, jusqu’à atteindre les limites, en doublant le nombre de paquets à chaque fois que le receveur accuse bonne réception de l’ensemble.
Tous les CDN ont donc une logique de slow start avec des round trip qui chargent de plus en plus de données à chaque « tour ». Au-delà de la taille qu’il est possible d’envoyer à chaque fois, le CDN doit également déterminer quels paquets envoyer dans quel ordre. Notamment arbitrer ce qui doit être priorisé entre le HTML, le JS et le CSS.
Faut-il envoyer un type de ressource complètement ou envoyer des morceaux de chaque type à chacune des itérations ?
Il s’avère qu’il est mieux d’envoyer un type de ressource complètement, notamment pour JS et CSS qui ne sont pas utilisables avant d’avoir été complètement envoyés. Ils ne sont pas streamable comme certains types d’image par exemple.
On découvre également qu’un grand nombre de serveurs n’appliquent pas les consignes demandées par les navigateurs en termes de priorités (Apache fait plutôt office de bon élève). Mais les navigateurs ne sont pas non plus d’accord entre eux sur la pondération des règles !
De même, les images en preload ont une priorité moindre que sans l’attribut (sic). Au-delà de l’aspect discutable de ces choix, ils portent à confusion pour les développeurs qui ne s’attendent pas à ces comportements et qui doivent gérer des différences selon les navigateurs.
Pour un CDN, il est difficile de connaître le nombre de paquets qu’il est possible d’envoyer.
En effet, côté client, la taille d’un lien est fixe mais souvent partagée entre plusieurs connexions, qui vont et qui viennent. Il est donc difficile de connaître précisément la capacité de la connexion à un instant T. Les CDN en sont donc réduits à l’estimer, de manière progressive, jusqu’à atteindre les limites, en doublant le nombre de paquets à chaque fois que le receveur accuse bonne réception de l’ensemble.
Tous les CDN ont donc une logique de slow start avec des round trip qui chargent de plus en plus de données à chaque « tour ». Au-delà de la taille qu’il est possible d’envoyer à chaque fois, le CDN doit également déterminer quels paquets envoyer dans quel ordre. Notamment arbitrer ce qui doit être priorisé entre le HTML, le JS et le CSS.
Faut-il envoyer un type de ressource complètement ou envoyer des morceaux de chaque type à chacune des itérations ?
Il s’avère qu’il est mieux d’envoyer un type de ressource complètement, notamment pour JS et CSS qui ne sont pas utilisables avant d’avoir été complètement envoyés. Ils ne sont pas streamable comme certains types d’image par exemple.
On découvre également qu’un grand nombre de serveurs n’appliquent pas les consignes demandées par les navigateurs en termes de priorités (Apache fait plutôt office de bon élève). Mais les navigateurs ne sont pas non plus d’accord entre eux sur la pondération des règles !
Safari en prend pour son grade, souvent qualifié de nouvel Internet Explorer. Il gère notamment la priorité des JS exactement de la même façon quelqu’ils soient (head, body, defer), à l’exception de ceux en async qui se voient affectés une priorité moindre.
De même, les images en preload ont une priorité moindre que sans l’attribut (sic). Au-delà de l’aspect discutable de ces choix, ils portent à confusion pour les développeurs qui ne s’attendent pas à ces comportements et qui doivent gérer des différences selon les navigateurs.

Un nouvel attribut,
Robin donne l’exemple des carrousels où la priorité de la première image se doit d’être haute quand celle des suivantes peut être basse.
fetchpriority permet aux développeurs d’expliciter la priorité à donner aux différents éléments.Robin donne l’exemple des carrousels où la priorité de la première image se doit d’être haute quand celle des suivantes peut être basse.

Finalement, l’auteur nous livre ce qui pourrait résumer en une phrase l’ensemble des conférences : « Le chargement de ressources n’est ni cohérent ni prédictible selon les conditions (navigateur, serveur, réseau…). Simplement l’observer dans son navigateur n’est pas suffisant. »

Mesure ou Meurs
Dans un superbe décor, Jean-Pierre Vincent fait un focus sur webpagetest pour mesurer la performance des sites.
Il pointe du doigt l’effet pervers des systèmes, comme Lightouse, qui donne des notes sur des critères donnés de manière automatique, ce qui incite les équipes à obtenir la meilleure note possible sans nécessairement comprendre ce qu’elles sont en train de faire.
On y apprend l’intérêt de savoir décrypter un waterfall, en commencant par le TTFB (Time to first byte), c'est-à-dire le temps d’attente avant de recevoir la réponse du serveur.
En performance, la taille de la ressource n’est pas forcément le critère numéro 1, c’est surtout l’impact sur l’utilisateur. Paradoxalement, on peut avoir des TTFB long pour des ressources légères et court pour des ressources lourdes avec des impacts utilisateurs inverses à ce qu’on pourrait imaginer au premier abord.
Un autre élément clé de la performance est le LCP (Largest Contentful Paint), à savoir l’élément ayant la plus grande surface visible à l’écran.
Le LCP est variable selon le terminal qui fait le rendu. Webpagetest indique en vert le LCP, ce qui permet se savoir à quel moment exactement, il est rendu. Une fois qu’on connaît cet élément, on va pouvoir libérer le chemin critique afin de faire en sorte qu’il soit chargé le plus tôt possible.
Pour mesurer la réactivité des sites, un indicateur historique est le First Input Delay (FID), qui n’est pas parfait car il mesure le délai entre un clic et un callback.
Il tend à être remplacé par l'Interaction to next paint (INP) qui mesure le temps entre le clic et le prochain affichage. Ces deux indicateurs ne sont toutefois pas simulables par des outils.
Le total blocking time est le temps passé entre le FCP et le Time to Interactive (TTI). Pour le réduire, il est important de trouver les scripts consommateurs, par exemple en les groupant dans Chrome dev tools.
Lighthouse peut également être utilisé en mode timespan, ce qui permet d’enregistrer les interactions et de détailler le temps passé.
En performance, la taille de la ressource n’est pas forcément le critère numéro 1, c’est surtout l’impact sur l’utilisateur. Paradoxalement, on peut avoir des TTFB long pour des ressources légères et court pour des ressources lourdes avec des impacts utilisateurs inverses à ce qu’on pourrait imaginer au premier abord.
Un autre élément clé de la performance est le LCP (Largest Contentful Paint), à savoir l’élément ayant la plus grande surface visible à l’écran.
Le LCP est variable selon le terminal qui fait le rendu. Webpagetest indique en vert le LCP, ce qui permet se savoir à quel moment exactement, il est rendu. Une fois qu’on connaît cet élément, on va pouvoir libérer le chemin critique afin de faire en sorte qu’il soit chargé le plus tôt possible.
Pour mesurer la réactivité des sites, un indicateur historique est le First Input Delay (FID), qui n’est pas parfait car il mesure le délai entre un clic et un callback.
Il tend à être remplacé par l'Interaction to next paint (INP) qui mesure le temps entre le clic et le prochain affichage. Ces deux indicateurs ne sont toutefois pas simulables par des outils.
Le total blocking time est le temps passé entre le FCP et le Time to Interactive (TTI). Pour le réduire, il est important de trouver les scripts consommateurs, par exemple en les groupant dans Chrome dev tools.
Lighthouse peut également être utilisé en mode timespan, ce qui permet d’enregistrer les interactions et de détailler le temps passé.
Comment devenir un Sherlock Holmes de la Web Performance
Ludovic Lefebvre revient sur son expérience chez Peaksys (filiale tech de cdiscount).Avec 20M de visiteurs par mois, on comprend que la performance est un enjeu.
Notre orateur vient nous présenter la méthode Sherlock, qui vise à passer de données à informations, puis connaissances et enfin sagesse.
Les connaissances sont très précieuses car elles sont réutilisables dans des contextes similaires.
Pour analyser une situation, on va généralement commencer par les observations, suivies des hypothèses, des expérimentations et enfin des conclusions.
Pour avoir une bonne visibilité, il est important d’être bien outillé, notatement niveau RUM (Real User Monitoring) et également performance d’infrastructure, APM et non régression.
Cette visibilité doit se compléter avec une vision claire de tous les changements (contenu, infrastructure, déploiement…). Ludovic prend le cas concret d’une augmentation du LCP (Largest Contentful Paint).
Pour comprendre ce qui s'était passé il a fallu s’appuyer sur les outils, notamment de RUM et le croiser avec l’historique des changements pour comprendre que cela résultait d’une opération de communication qui avait entraîné le retrait du bandeau sur le site. Cela a eu pour effet de dégrader le LCP.
Enfin, Ludovic nous offre un parallèle du biais du survivant avec l’anecdote bien connue des avions endommagés qui sont revenus à la base après la seconde guerre mondiale.
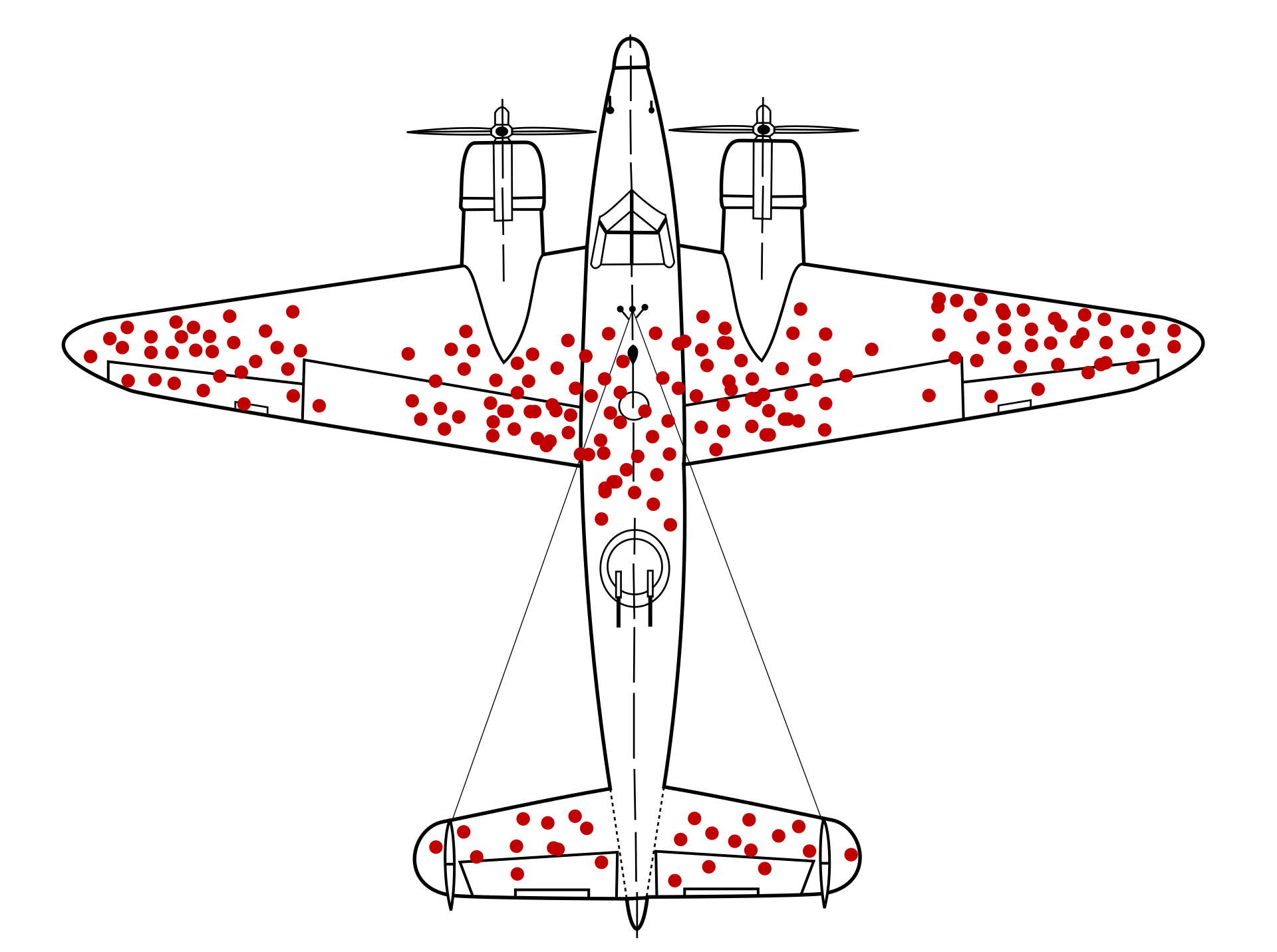
La première réaction a été de renforcer les zones endommagées avant de comprendre que les zones à améliorer étaient celles qui n’étaient pas endommagées car relatives aux avions qui n’étaient pas revenus.
Dans le web, le constat est applicable dans la web performance où les avions s’apparentent aux utilisateurs et le champ de bataille au tunnel de conversion.
Il ne faut pas analyser les utilisateurs qui arrivent en bout de tunnel car ce sont ceux qui commandent et qui ont donc atteint le résultat escompté. Il faut au contraire se pencher sur tous les autres.
Dans le web, le constat est applicable dans la web performance où les avions s’apparentent aux utilisateurs et le champ de bataille au tunnel de conversion.
Il ne faut pas analyser les utilisateurs qui arrivent en bout de tunnel car ce sont ceux qui commandent et qui ont donc atteint le résultat escompté. Il faut au contraire se pencher sur tous les autres.
L'art de l'observabilité avec Open Telemetry
Un atelier proposé par un intervenant de Dynatrace, qui a su garder un bon focus sur Open Telemetry plutôt que sur Dynatrace, un excellent point.OpenTelemetry cible l'observalité (je comprends ce qui se passe) plutôt que le monitoring (je constate ce qui se passe).
Il vise à standardiser la production de métriques, logs, traces, profiling. Il est né sur les cendres de la fusion entre OpenTracing et OpenCensus.

Cette standardisation permet d'homogénéiser les pratiques, plutôt que d'avoir des multitudes d'outils qui sont spécialisés dans leur domaine (réseau, application…) et pas nécessairement interopérables. Il faut toutefois garder en tête que c’est d’une part un standard vivant, avec des choses restant à formaliser et que le niveau des outils varie d’une stack technique à l’autre.
Concrètement, on peut imaginer avec des traces formalisées suivre le parcours complet d'une requête d'un visiteur sur une app, depuis l'instrumentation du front jusqu'aux infrastructures et définir exactement quel temps il a passé dans quel composant afin de diagnostiquer les éventuelles erreurs / lenteurs.
La télémétrie s’articule autour de deux composants clés : l’instrumentation et le collecteur. L’objectif de standardiser ce dernier est d’éviter d’avoir un collecteur spécifique par type de logs ou traces mais plutôt un générique et agnostique des plateformes ciblées.
OpenTelemetry est actuellement le projet le plus dynamique porté par la CNCF derrière Kubernetes. Pas étonnant qu’il soit au cœur de notre plan d’action technique cette année.
La télémétrie s’articule autour de deux composants clés : l’instrumentation et le collecteur. L’objectif de standardiser ce dernier est d’éviter d’avoir un collecteur spécifique par type de logs ou traces mais plutôt un générique et agnostique des plateformes ciblées.
OpenTelemetry est actuellement le projet le plus dynamique porté par la CNCF derrière Kubernetes. Pas étonnant qu’il soit au cœur de notre plan d’action technique cette année.
Soft navigation
Yoav Weiss nous propose une conférence teintée d’humour sur la soft navigation. Par soft navigation, on entend le contrôle de la navigation côté app, notamment dans le cadre des SPA (qui manipule la navigation et l’historique).Le fond du débat tournait donc autour de SPA (single page app) vs MPA (multiple page app). Yoav travaille sur Google Chrome. À la question quelle architecture est plus performante, il répond : « on ne sait pas ». Globalement, mesurer la performance d’une SPA est toujours aussi complexe, bien que le sujet soit ouvert depuis plus de 10 ans.
Du côté des implémenteurs de navigateur, la gestion de l’historique par les applications est complexe car assez tributaire de l’usage des framework ou lib sous jacente. Par exemple, certains vont déclencher
history.pushState dès que l’utilisateur interagit avec la page (click par exemple), d’autres une fois seulement que la nouvelle vue est rendue, ce qui rend complexe la détermination du point de départ.D’autre part, les SPA ne font pas bon ménage avec les web core vitals. En effet, on ne mesure que le premier chargement qui est généralement le plus lent, avec la promesse que la navigation secondaire sera plus rapide, mais invisible par le navigateur.
Une nouvelle API voit le jour : Navigation API, qui est actuellement uniquement supportée par Chrome. Avec cette API, on peut visualiser dans les chrome tools les même métriques que pour la navigation primaire et également disposer d’API de mesure de la performance
PerformanceObserver.Les API sont accessibles derrières un flag expérimental qu’il est possible d’activer dès à présent (
reportSoftNavsde ).Le top 10 des perles en webperformance
Stéphanie Rios nous offre une compilation des perles qu’il croise au quotidien.Le lazyloading c’est bien mais trop de lazyloading tue le lazyloading. La règle d’or : ne lazyloader que les images qui ne sont pas visibles dans le viewport.
Si on lazyload une image qui est visible dans le viewport, on retarde le temps de chargement général. Soit on utilise une lib de lazyload et le chargement de l’image sera tributaire du chargement de cette lib, soit on utilise le lazyload natif et cette image sera dépriorisée.
Il nous conseille également de privilégier les lib plutôt que le lazy load natif qu’il ne juge pas suffisamment « agressif ». En effet, le lazyload natif peut charger des contenus qui ne seront potentiellement jamais vu, car accessible 2-3 viewport plus bas dans la page.
Le defer peut parfois s’avérer contre productif. Chargé trop tôt dans le document il peut bloquer le téléchargement d’autres ressources. Les directives
@import CSS, notamment pour les google fonts peuvent également occasionner des blocages. On trouve également des fonts servies en OTF au lieu de WOFF2 (qui est lui un format compressé à privilégier).Les appels à des domaines externes sont parfois aussi sources de blocages. Des scripts third party sont parfois chargés de manières bloquantes sur des domaines externes, ce qui pose des problèmes en situation de mobilité. En plus de cela, le bénéfice est parfois anecdotique dans le cadre de polyfill qui ne seront pas utilisés si la fonctionnalité est supportée nativement.
Côté mise en cache des lib third party par l’usage d’un CDN, notre speaker nous rappelle que depuis quelques années la clé de cache des ressources externes est doublée avec le host de l’origine. Si une lib est chargée depuis un domaine A et qu’elle est également demandée sur un domaine B, elle sera quand même rechargée.
Certaines ressources manquent souvent à l’appel en termes de lazyload, on peut notamment citer le player youtube, très gourmand en ressources. Il est possible de le mettre dans une iframe et lazyloader cette dernière.
On trouve souvent des images responsives qui ne le sont pas, par exemple la même image en desktop et en mobile ou des erreurs de media queries.
Enfin, il faut maintenant abolir les sprites, qui sont des concaténations d’image avec des références à la position de l’image à afficher.
On se retrouve donc à charger des sprites potentiellement lourd, parfois sur mobile, pour utiliser seulement quelques images de ce dernier.
Maintenant que l’on dispose de HTTP/2 qui permet de multiplexer les contenus sur une même connexion, cela n’a plus d’intérêt.
Conclusion
Cette ultime conférence marquait la fin de cette belle édition. On en retiendra que la web performance nécessite des piqûres de rappel fréquentes sur des notions qui peuvent sembler acquises. Elle demande également un peu de subtilité pour des comportements qui peuvent parfois s’avérer contre-intuitifs.Enfin, la web performance doit se construire avec les équipes de dév et pas à leur détriment ni après coup.
On saluera également pour cette conférence une organisation soignée et jamais mise en défaut. Merci aux organisateurs !

À lire aussi

9 mars 2026
JTE : un moteur de templates moderne, rapide et sécurisé pour Java

16 février 2026
La Sobriété Numérique, de la quantification des émissions carbone des applications à la mise en œuvre des corrections

6 janvier 2026
Introduction pratique au Q-learning avec Gymnasium Taxi-v3

9 décembre 2025