

Article écrit par Clément Alexandre
Alors qu’on parle de connexion pair à pair, si l’on regarde les cas d’usage de WebRTC en ligne, on pourra être surpris de constater que des serveurs centraux sont quasiment toujours requis (signaling, STUN/TURN).
Heureusement, comme le suggère l’article MDN sur le WebRTC, on devrait très bien pouvoir établir une connexion WebRTC par pigeon voyageur.
C’est donc précisément ce que nous allons faire !

Je vous propose ici une incursion dans les protocoles en jeu pour la communication WebRTC, où nous allons particulièrement bien faire la distinction entre la mise en relation des pairs et la transmission des données. En effet, les exemples que l’on peut trouver en ligne ont une fâcheuse tendance à mélanger le code destiné respectivement à chaque pair (car il est souvent fait exemple de deux clients JavaScript exécutés dans une même page)
Dans la deuxième partie de cet article, nous remplacerons notre système de connexion aviaire par un autre peut-être plus performant, sur la base d’un petit serveur Elixir fait-main.
Introduction à WebRTC
On a beaucoup entendu parler de la technologie WebRTC (pour Web Real Time Communication) à travers les outils qui nous ont permis de continuer à travailler pendant le confinement : Zoom, Meet, Skype, Livestorm (français) ou Jitsi (open-source) pour ne citer qu’eux. Globalement, on ne prend pas grand risque à affirmer que l’intégralité des services multimedia qui opèrent dans le navigateur utilisent désormais cette technologie. C’est d’autant plus vrai depuis que les plugins propriétaires Flash ou ActiveX qui assuraient ces fonctionnalités avancées ne sont tout simplement plus supportés par les navigateurs.
Au début, il y avait eMule
WebRTC répond à deux manques qui n’étaient pas encore couverts de manière standardisée (par les WebSockets notamment) :
- Permettre à un navigateur de se connecter à un serveur (ou tout autre dispositif) en UDP plutôt qu’en TCP (pour obtenir des latences de communication les plus faibles possible) ;
- Permettre à deux navigateurs de se connecter en direct, sans que les données ne transitent par un serveur ou un relais quelconque.
Bref, du peer to peer en UDP, ce que l’on fait depuis vingt ans lorsque l’on joue à n’importe quel jeu multijoueur ou que l’on télécharge des fichiers via eMule BitTorrent.
Supporté par les acteurs majeurs (Google, Apple, Microsoft, Mozilla…), WebRTC est un standard de facto dont la spécification n’est pourtant pas encore complète. En effet, malgré quelques disparités parfois polémiques dans son implémentation à travers les navigateurs, on devrait pouvoir en avoir un usage assez intensif pour la quasi-totalité d’entre eux. Enfin, WebRTC dispose de bibliothèques pour être également utilisé sur la majorité des plateformes natives (mobile et bureau).
En tant que protocole de haut-niveau, l’implémentation WebRTC peut-être (très grossièrement) vue comme une API assortie d’une porte d’entrée TCP/UDP ouverte dans le navigateur. Tout le reste de l’implémentation est déléguée à d’autres protocoles existants (si vous avez déjà lu quelques articles sur le sujet, je fais référence à STUN, TURN, ICE, SDP et autres acronymes sur lesquels je reviendrais ci-après pour certains d’entre eux).
Quelques challenges techniques
Sans aller très loin dans le détail des différents protocoles en jeu, on peut comprendre pourquoi connecter deux navigateurs entre eux n’est pas aussi trivial qu’il n’y paraît. Tout d’abord le navigateur est utilisé à partir d’un ordinateur qui n’est pas connecté directement à Internet, mais via une box opérateur, un réseau virtuel ou n’importe quel équipement réseau intermédiaire.
Il faut donc un service qui permette à chacun de savoir comment être contacté soi-même, avant même de commencer à établir une communication. Les caractéristiques de connectivité de chacun sont déterminées à l’aide du protocole ICE (pour Interactive Connectivity Establishment), qui s’appuie lui-même sur les protocoles STUN et TURN (cf. ci-dessous). En résumé, un «candidat ICE» va donc contenir l’ensemble des informations de connectivité d’un pair qui lui permettent d’être joint.
STUN & TURN
C’est ici que le serveur STUN (pour Simple Traversal of UDP through NAT) est indispensable. NAT est la technologie qui permet de relayer le trafic réseau entrant par la box vers le bon équipement à la maison. Un serveur STUN permet donc simplement de faire une sorte de ping-pong et de savoir soi-même comment notre navigateur est vu depuis l’extérieur de notre réseau domestique (IP publique de la box, port utilisé…), afin de transmettre ces informations à l’équipement final avec lequel on souhaite établir une connexion.
Parfois, un pare-feu ou la box Internet va bloquer le trafic des équipements auxquels on n’est pas déjà connecté (pour mémoire, c’est le «Symetric NAT») ; ça rend l’établissement d’une connexion impossible entre deux équipements situés dans des réseaux privés jusqu’alors «inconnus». C’est ici qu’intervient le serveur relai TURN (POUR Traversal Using Relays around NAT) : installé au beau milieu de l’Internet public, il va passer les paquets de données d’un pair à l’autre. C’est une sorte de solution de secours pour garantir au WebRTC de fonctionner en toutes circonstances, même de manière dégradée. Habile.
Vous pouvez héberger vos propres serveurs STUN et TURN. Voici quelques implémentations : Stuntman (STUN seul) ou Coturn (STUN et TURN — on trouve d’ailleurs une image Docker qui semble fort bien maintenue pour ce dernier).
On peut aussi utiliser des serveurs publics à des fins de développement, comme le serveur STUN de Mozilla : stun.services.mozilla.com. Trouver un TURN public est plus délicat, car son usage est assez intensif en bande passante. Bien qu’un serveur STUN/TURN ne soit pas nécessaire pour des expérimentations qui ne quittent pas son propre poste localhost, ils deviennent tous les deux incontournables pour connecter des équipements distants.
Le signalement (Signaling)

C’est bien beau d’avoir la technologie pour faire transiter de la vidéo pour une consultation en visio avec son médecin, encore faut-il prendre rendez-vous.
Pour cette problématique, rien n’est propre à WebRTC : la plupart des applications peer to peer utilisent des serveurs afin de gérer les communications sur le service. C’est par exemple le cas des serveurs trackers BitTorrent qui consignent de manière plus où moins redondante et distribuée qui dispose de quel fichier, pour permettre au demandeur de se connecter au bon receleur pair.
Le développement de l’application de mise en relation sera peut-être autant, voire plus fastidieuse que l’implémentation de la communication elle-même… D’autant que WebRTC se garde bien de nous fournir la moindre indication sur la marche à suivre. Mais c’est normal, car comme on le verra un peu plus tard, ce n’est simplement pas son domaine.
En selle !
Dans cette première partie, on va établir une connexion WebRTC entre deux pairs (potentiellement distants de plusieurs centaines de kilomètres) sans serveur de Signaling; afin de bien isoler la logique de signaling que l’on mettra en place dans la deuxième partie de cet article.
Note concernant les sessions SDP
De manière complètement transparente, nous allons faire un usage assez intensif du protocole SDP (pour Session Description Protocol) dans nos usages de WebRTC. Il s’agit du protocole qui va embarquer la description de la mise en route de l’échange pair à pair et ce qu’ils ont à proposer comme contenu : audio, video (ainsi que les codecs de compression utilisés) ou encore un flux de données brutes. Parmi les usages plus connus de SDP, on trouve notamment les appels par téléphones IP — dont le protocole SIP d’établissement d’une session de VoIP entre deux appareils mobiles se base d’ailleurs… sur STUN/TURN !
1. Créons une offre de Session et transmettons nos informations
C’est parti pour l’expérimentation. Nous allons globalement suivre le diagramme suivant : 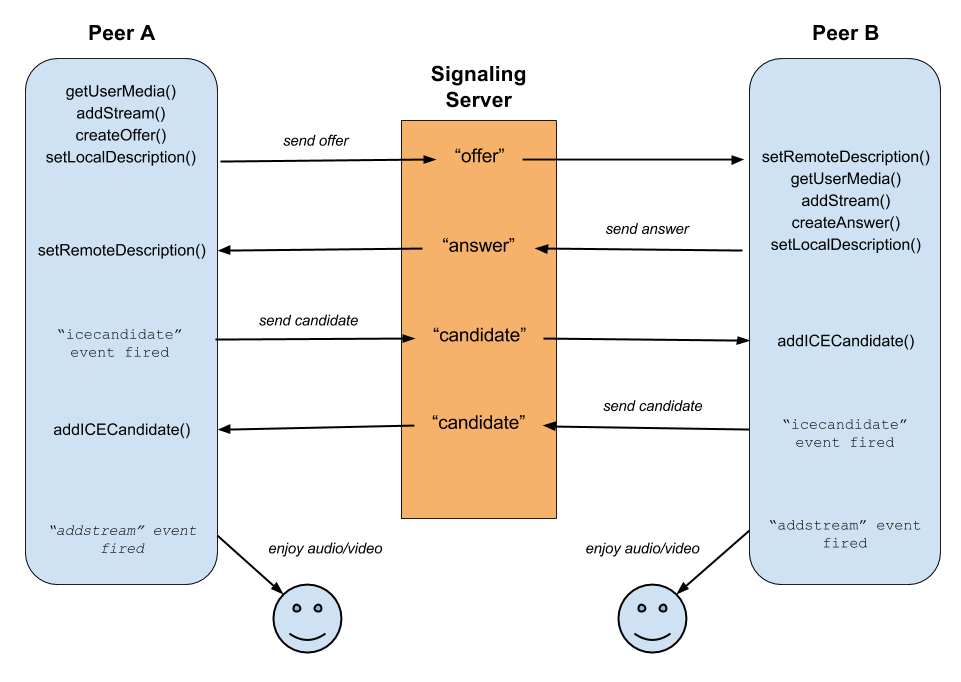 https://github.com/satanas/simple-signaling-server
https://github.com/satanas/simple-signaling-server
Je vous ai préparé une petite interface pour faciliter la saisie des informations échangées :
- Ouvrez un nouvel onglet et rendez-vous sur cette page.
- Demandez à un ami qui habite Jokkmokk d’ouvrir quant à lui cette page-ci.
Vous pouvez ensuite commencer par cliquer sur le bouton Créer une offre SDP de votre côté. En sous-main, la page crée automatiquement une offre assortie d’un datachannel pour l’échange de données.
Vous devriez voir s’afficher deux informations :
- Une description d’offre de session SDP, qui décrit à votre interlocuteur que vous souhaitez correspondre via un datachannel, de la donnée brute (on pourrait initier un flux webcam ici) ;
- La liste de vos informations ICE. Celles-ci décrivent à votre interlocuteur comment vous joindre.
C’est le moment de prendre votre plus belle plume et de recopier ces deux lots d’informations sur un morceau de papier à attacher à votre messagerie volante.
2. Laissons notre correspondant répondre à notre offre
Lorsque votre correspondant à Jokkmokk a reçu le courrier, il devra cliquer sur Coller une offre SDP, où il recopiera le contenu du parchemin. Il fera de même avec les identifiants ICE reçus.
Votre correspondant verra alors s’afficher deux données à vous transmettre en retour :
- La réponse à votre offre SDP ;
- Ses données ICE.
Une fois ces nouvelles informations en votre possession, il ne vous reste qu’à les recopier en cliquant sur les boutons adaptés.
3. Envoyons enfin des données en peer to peer
Vous devriez alors voir s’ouvrir le canal de données qui était décrit dans l’offre que vous avez envoyée.
Si vous cliquez sur le bouton Envoyer un mot, votre correspondant devrait pouvoir vous lire !
Le message aura alors, dans la plupart des cas, transité en UDP sans avoir été relayé par un serveur central (sauf si un serveur TURN était nécessaire).
La suite au prochain épisode
C’est tout pour cette première partie ! Prochainement, nous mettrons en place un serveur de signaling afin d’automatiser l’établissement de la connexion entre pairs. Nous tâcherons également d’enrichir quelque peu nos échanges.
En attendant de vous retrouver, voici quelques liens qui valent le détour :
À lire aussi

JTE : un moteur de templates moderne, rapide et sécurisé pour Java

La Sobriété Numérique, de la quantification des émissions carbone des applications à la mise en œuvre des corrections

Introduction pratique au Q-learning avec Gymnasium Taxi-v3
